
티스토리 뷰
1. 힙 자료구조 개념
힙(Heap)은 우선순위 큐(Priority Queue) 구현을 위해 사용하는 자료구조입니다.
실제 제가 준비 중인 사내 알고리즘 시험에서도 가장 자주 사용되고 있습니다.
힙과 우선순위 큐를 이해하기 전에 큐 자료구조에 대해 이해를 하면 좋습니다.
큐에 대한 소개는 아래 링크 참고 바랍니다.
https://rightbellboy.tistory.com/343
큐 자료구조 개념 설명 및 예시 코드 (C/C++)
1. 큐 자료구조 개념 설명큐(Queue)는 가장 간단한 자료구조 중 하나로 FIFO(First In First Out)의 특성을 가지고 있습니다.FIFO는 큐에 먼저 들어온 데이터가 먼저 나간다는 의미이고,은행이나 맛집에서
rightbellboy.tistory.com
우선 순위 큐는 일반적인 큐와는 다르게 데이터를 뺄 때, 즉 dequeue시
자료 구조 내에서 우선 순위가 가장 높은 데이터가 나오게 됩니다.
이러한 형태로 우선 순위대로 데이터를 뽑을 수 있는 자료구조를 우선 순위 큐라고 하고,
이러한 우선 순위 큐를 완전 이진 트리 형태로 구현하면 '힙'이라고 표현합니다.
통상적으로 우선 순위는 데이터 값의 최소값 혹은 최대값으로 정하는데
그 특성에 따라 min heap, 혹은 max heap이라고 불리고 있습니다.
max heap은 큰 값이 높은 우선 순위를 갖는 형태이므로
pop을 할 경우 해당 heap 내에서 가장 큰 값이 나오게 됩니다.
(heap에서의 deque는 pop, enque는 push라고 칭합니다)
앞서 언급했듯이 힙은 완전 이진 트리 구조 형태로 구현됩니다.
따라서 최대값을 꺼내고 힙을 재배열할 때 최악의 경우 O(n)이 아닌 O(logn)의 시간복잡도를 갖게 됩니다.
(또한 데이터를 넣을 때도 O(logn)의 시간복잡도를 갖게 됩니다)
이러한 특성이 있기 때문에 자료구조에서 데이터가 빈번하게 들어오고 나가지만,
매번 가장 큰 값이나 가장 작은 값을 찾는 경우라면 힙을 사용하면 유용합니다.
만약 위 같은 상황에서 힙이 아닌 정렬을 사용하게 된다면 오히려 시간 비용이 훨씬 커집니다.
반대로 데이터를 빼는 경우가 적은 상황이라면 아무데나(통상 맨 끝) 저장해두고
필요할 때 한 번 씩 정렬해서 사용하는 형태로 쓰는 것이 유리합니다.
2. 힙 자료구조 구현 방식
heap에 대한 개념 설명은 마치고 1차원 배열을 사용하여 구현하는 방법을 설명해보겠습니다. (min heap)
데이터가 아래와 같이 들어있는 상태라고 보고, push, pop 시 어떻게 동작하는지 확인해보겠습니다.

min heap은 아래 2가지 규칙을 만족시켜야 합니다.
- 완전 이진 트리여야 한다. (자식 최대 2개, 왼쪽 위부터 순차적으로 채워져야 함)
- 부모 노드의 값은 모든 자식 노드의 값보다 작거나 같아야 한다.
2.1. push
heap에 5를 넣을 때 어떻게 동작하는지 해보겠습니다. (push(5))
우선 새롭게 들어가는 값 5를 heap의 가장 마지막 자리에 추가합니다.
(기본적으로 heap에서 push는 마지막 leaf 노드에, pop은 root 노드에서 진행합니다)
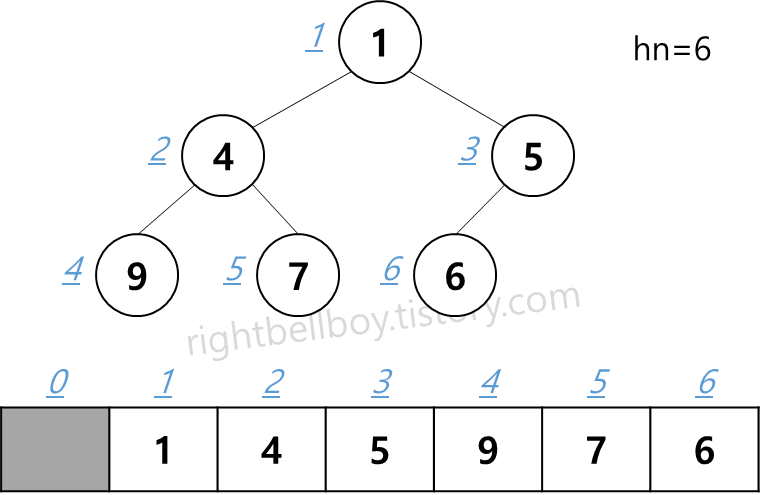
여기서 hn(heap size)이 5에서 6으로 1 증가합니다.

새롭게 들어간 5는 무작정 마지막에 넣은 값이기 때문에 대부분 기존 heap 규칙에 위배됩니다.
이 경우 추가된 값(6번 index의 5)이 부모(3번 index의 6)보다 작기 때문에 min heap의 규칙을 어긴 상태입니다.
따라서 추가된 노드와 부모 노드의 위치를 서로 바꿔줍니다.

이 작업(비교/swap)을 최상단 root 노드까지 반복하여 진행하면 됩니다.
이번엔 자리를 한 칸 위로 옮겨서 index 3와 그 부모 index 1의 값을 비교합니다.
이 경우 부모(1)가 자식(5)보다 작으므로 min heap이 완성된 것으로 보고 비교/swap을 종료하면 됩니다.

push 동작 방식을 정리하면 아래와 같습니다.
1) 가장 마지막 자리에 새로운 값을 넣는다.
2) 새로 들어간 값을 바로 위 부모와 비교하고, 부모보다 우선순위가 높은 경우 swap 한다.
3) 위로 한 칸 이동하여 비교/swap을 반복한다.
4) 부모의 우선순위가 높지 않거나, 최상단에 도달한 경우 종료한다.
2.2. pop
앞서 설명했던 push(5)까지 마친 상태에서 pop을 해보겠습니다.
물론 최상단(1번 index)에 있는 값 1을 return하는 것은 명확합니다.
여기서는 비어진 최상단을 채우면서 min heap 구조를 유지하는 방식을 소개하겠습니다.
우선 root 노드의 1과 마지막 자리에 있던 6을 바꿉니다.
여기서 heap size가 6에서 5로 1 감소합니다.

그리고 자식 노드들 중 더 작은 값을 찾아 비교합니다. (이 경우 2번 index의 4)
여기서 둘 중 더 작은 값을 선택하지 않으면 min heap 구조가 깨지므로 주의합니다.
새롭게 root에 올라온 값(6)이 자식(4)보다 크거나 같으므로 자리를 교환합니다.

아래로 한 칸 내려간 뒤 다시 자식 노드들 중 더 작은 값을 찾고 비교합니다. (이 경우 5번 index의 7)
이 경우 해당 값(6)이 모든 자식들 보다 작으므로 min heap이 완성된 것으로 보고 비교/swap을 종료합니다.

pop 동작 방식을 정리하면 아래와 같습니다.
1) root 노드의 값과 가장 마지막 자리의 값을 교환한다.(가장 마지막 자리의 값이 pop된 값)
2) root 노드로 이동한 값을 2개의 자식 중 더 우선순위가 높은 값과 비교하고, 부모보다 우선순위가 높은 경우 swap 한다.
3) 아래(swap한 위치)로 한 칸 이동하여 비교/swap을 반복한다.
4) 2개 자식 모두 해당 값보다 우선순위가 높지 않거나, 마지막 노드에 도달한 경우 종료한다.
5) hn + 1 자리에 있는 값을 return한다. (최상단에 있던 값)
2.3. 0 base가 아닌 1 base로 구현한 이유
자료구조의 index는 0부터 시작하는 것이 일반적이나(0 base)
자식 ↔ 부모 간 index 처리를 간편하게 하기 위해 1 base로 구현했습니다.
이진 트리를 1 base로 구현할 경우 자식 index 나누기 2는 무조건 부모 index가 되어 편리합니다.
1 base로 구현하는 경우 root인 1의 자식이 2, 3이 되는데, 2 / 2와 3 / 2는 모두 1이 됩니다.
반대로 0 base로 구현하면 0의 자식이 1, 2인데, 1 / 2는 0이지만 2 / 2는 0이 아닌 1이 됩니다.
따라서 (자식 index - 1) / 2로 처리해야 부모 index를 구할 수 있습니다.
이러한 절차가 번거롭기 때문에 0번 index 1자리를 포기하고 1 base로 구현합니다.
3. 힙 자료구조 코드
앞서 설명한 swap 방식으로 구현한 코드입니다.
#include <cstdio>
const int LM = 7; // 1 base (6 + 1)
int h[LM], hn, c;
void swap(int c1, int c2) {
int tmp = h[c1];
h[c1] = h[c2];
h[c2] = tmp;
}
void push(int v) {
h[++hn] = v;
for (c = hn; c > 1; c /= 2) {
if (h[c] < h[c / 2]) swap(c, c / 2);
else break;
}
}
int pop() {
if (hn <= 0) return -1; // empty
swap(1, hn--);
for (c = 2; c <= hn; c *= 2) {
if (c + 1 <= hn && h[c + 1] < h[c]) c += 1;
if (h[c] < h[c / 2]) swap(c, c / 2);
else break;
}
return h[hn + 1];
}
void printHeapArr() {
printf("heap arr: ");
for (int i = 1; i <= LM - 1; ++i) printf("%d ", h[i]);
printf("(hn: %d)\n", hn);
}
int main() {
hn = 0;
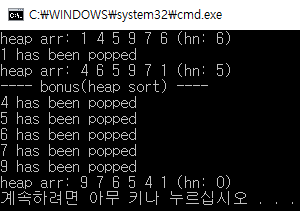
push(1), push(4), push(6), push(9), push(7);
push(5);
printHeapArr();
printf("%d has been popped\n", pop());
printHeapArr();
// bonus (heap sort)
printf("---- bonus(heap sort) ----\n");
printf("%d has been popped\n", pop());
printf("%d has been popped\n", pop());
printf("%d has been popped\n", pop());
printf("%d has been popped\n", pop());
printf("%d has been popped\n", pop());
printHeapArr();
return 0;
}
추가로 성능 최적화된 no swap 버전은 아래 링크 참고하시면 됩니다.
https://rightbellboy.tistory.com/359
힙 자료구조 구현(no swap version) (c/c++)
이 페이지는 swap을 하지 않는 힙 자료구조 구현에 대한 설명입니다.응용 버전이기 때문에 전반적인 개념과 기본적인 구현법을 알고 싶으시면 아래 링크 참고해주시면 됩니다.https://rightbellboy.tist
rightbellboy.tistory.com
'개발자 > 자료구조,알고리즘(C)' 카테고리의 다른 글
| 힙 자료구조 구현(no swap version) (c/c++) (0) | 2026.03.03 |
|---|---|
| 큐 자료구조 개념 및 구현(w/ 배열) (C/C++) (0) | 2024.09.23 |
- Total
- Today
- Yesterday
- 아가별
- 정세현의통찰
- 쿠프마케팅
- 관계가상처가되기전에
- 당신도느리게나이들수있습니다
- 자동차보험
- 시대예보
- 자료구조
- JUNGOL
- 독서감상평
- 여가포인트
- 삼성전자
- 나의첫죽음학수업
- 유연함의힘
- 마침내 특이점이 시작된다
- 세상을 읽는 새로운 언어 빅데이터
- 이용제한
- 동탄에듀센터2
- 영화감상평
- 시스템개발자
- 인간본성불패의법칙
- 알고리즘
- 독서 감상평
- 정올
- 동탄에듀센터
- 똑똑하고게으르게
- 이상감지
- 센터독서클럽
- 문현공
- 최재천의공부
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |